
[Student IDEAS] by Karen Taubenberger and Michelle Diaz - Master in Management at ESSEC Business School
This article explores the legal and existential tension between generative AI and copyright law, arguing that the depletion of human-generated data poses a threat to AI’s own development. By analyzing cases like Kashtanova and Getty Images, it highlights the "grey zones" of authorship and the risk of "model collapse" when AI is forced to train on its own synthetic outputs. Ultimately, the author contends that protecting creators through new licensing models is essential to prevent a "world starved of creativity" and ensure a high-quality data supply for future innovation.
---
On March 25, 2025, OpenAI dropped a new image-generation feature with its GPT-4o release, stirring immediate controversy1. The tool lets users whip up stylized visuals that eerily mimic the signature styles of iconic studios like Studio Ghibli. Notably, co-founder Hayao Miyazaki, a fierce critic of AI art, slammed it as “an insult to life itself2”.
Similarly, the Writers Guild of America (WGA) went on a months-long strike in 2023 over fears that generative AI threatens writers’ livelihoods, halting production on numerous TV shows and films. At the same time, headlines have been flooded with copyright infringement claims during AI model training. All this seems to point to one thing: Generative AI has a copyright problem. In the mid- to long-term, this isn’t just a problem for creators: AI companies might feel the fallout too.
Generative AI (GenAI) refers to artificial intelligence systems designed to create original content, rather than just analyzing existing data. These systems generate new material by identifying and learning complex patterns from vast datasets using different techniques. For instance, they can understand and generate text by recognizing relationships between words (transformers3) or identify key features in images, sounds, or designs and use them to create new versions (autoencoders4). This ability to independently create instigates concern on who should be credited as the creator, how rights should be assigned, and whether such creations can be legally protected5.
Copyright was built for a human world, with its earliest statute dating back to 1710. Originally designed to protect “literary, scientific, and artistic works” such as poems, films, or songs6. It grants creators exclusive rights that fall into two categories: economic rights, which allow them to control and earn from the use of their work, and moral rights, which protect their personal connection by ensuring they are credited and can prevent changes that alter the original. In the EU, these protections last for 70 years after the creator’s death7.
Importantly, the moment you create something original, it’s protected. “All rights reserved” is applied automatically, no formal registration needed. However, one core principle underpins all copyright law: the author must be human.
That’s where things get complicated in the world of AI. For instance, if a programmer (a human) writes software code, that work is protected by copyright8. Similarly, if a human writes the training code that enables a machine-learning model to function, that code is protected. But what about the output of the model itself? Going forward, one of the most tricky issues will be around authorship and ownership of works created and co-created by AI.
Historically, copyright has been quite clear in terms of ownership. Whoever or whatever entity creates a certain piece of work/way of working clearly owns the rights so long as they are able to prove and register ownership. In a sense, there’s a clear thread between what is produced and the human/s that were involved in the production.
In an age where one can produce or create something that is not entirely human-made or can be a combination of both(purely human-made and co-created by AI), where do we draw the line? In 2023, the US Copyright Office made a clear stance on the sufficiency of human authorship required to be copyrightable. The US Copyright Office ruled on Kashtanova, a case on AI-generated imagery in creative works. The case involved a graphic novel that combined human-written text and imagery produced by Midjourney (AI image generator). Essentially, the Office ruled that it could not register the images, given that no matter how detailed the text-prompts were, the AI’s output remains unpredictable and therefore beyond the artist’s direct control. The Kashtanova case created a precedent and cases following it remained true to the strict requirement of human authorship: “human authorship is the bedrock requirement of copyright9.”
However, the US Copyright Office did not unilaterally dismiss the possibility that a human might be recognised as an author of an AI-generated piece of work. But the office didn’t exactly lay out clear guidelines either. To have a good chance of registering a claim of authorship, the human/s involved must either prove heavy involvement in the creation of the work (training input of the model, process, etc) or demonstrate sufficient human authorship10.
This leaves legal grey zones even in everyday life. Would one need to cite AI-generated images in a presentation for example? If they are not subject to copyright this should not be necessary (similar to an open source picture). But yet, a check of the citation requirements of different universities results in very different opinions on this matter (and also APA 7th or Chicago: citation styles used in academic writing, have no clear guideline).
Perhaps more complicated and difficult than delineating what combination and weightage of AI and human authorship combo can be protected by law, is the actual enforcement of the law itself. And whether the large-scale harvesting of organic (human created) works should be illegal under existing copyright laws.
Consider how a claimant might prove authorship of an AI-generated work. Or alternatively, how one might dispute the claim that a work is not AI-generated in some way. Where does the burden of proof lie? Proving an AI made something is difficult since the AI can give different results even with the same prompt, and AI companies refuse to take responsibility for their outputs. OpenAI’s terms mention “acknowledge that multiple users might receive identical or similar results”, while Microsoft's Copilot terms contain similar provisions11. This traceability problem matters most once a work goes public, since copyright protection and authorship only kick in when something is actually shared (aka diffusion). This inability to draw a clear line poses issues for users that seek to claim rights for commercial purposes.
This lack of clearly defined ownership further becomes problematic once you consider what happens to the data. Microsoft Copilot and similar services include terms that allow companies to use any data you upload to train and further improve their AI. In other words, users are not only unable to claim ownership of outputs, they also give the companies consent to use their own inputs to generate new content. Thus creating a double bind: you have no right to what the AI produces, and the company gains rights to everything you feed the AI. A clearly asymmetrical benefit.
Another case that highlights this issue is the legal battle between Getty Images and Stability AI. Essentially, Stable Diffusion, a product by Stability AI “was trained on 2.3bn images from a third-party website which pulled its training images from the web, including copyright image archives such as Getty and Shutterstock12.” Hence, the core question at the heart of the legal debate is whether this large-scale harvesting of organic (human created) images should be banned under the current copyright laws.
As of November 2025, Getty Images lost their copyright infringement claims, while narrowly winning trademark claims. In essence, the court arrived at these decisions since:
So how do you draw the line between necessary information usage and copyright infringement? Is it in the contention between how much AI is in a particular piece of work and how much human involvement is required? Or perhaps it comes down to technicalities like where the training occurs, as illustrated by the Getty Images case?
Or is it around the commercialization of the model, what is a fair price for the information a model uses for the monetisation of that information? Is it the ability of a model to generate “near verbatim” pieces of work14?
After all, LLM makers can easily deflect blame for problematic outputs by claiming users simply didn't prompt effectively enough. Since prompting has become an essential skill everyone is learning. In essence, the LLM companies can pass on blame to the users, since they did the prompting, and should therefore be responsible for the output. What a convenient way to shift accountability from LLMs providers to consumers; a classic attention economy dynamic where end-users bear responsibility as companies attempt to escape scrutiny.
Another vital consideration going forward with AI is the availability of data on which it is trained on, given the speed at which the foundational models are eating up data to continuously improve their output. As incentives for creators erode, original content grows rarer, while AI-generated material increasingly saturates the internet, feeding feedback loops.
According to a San Francisco-based AI research group, Epoch AI, at the current rate at which models are eating data, the total amount of human-generated content found on the internet could run out as early as 2026:
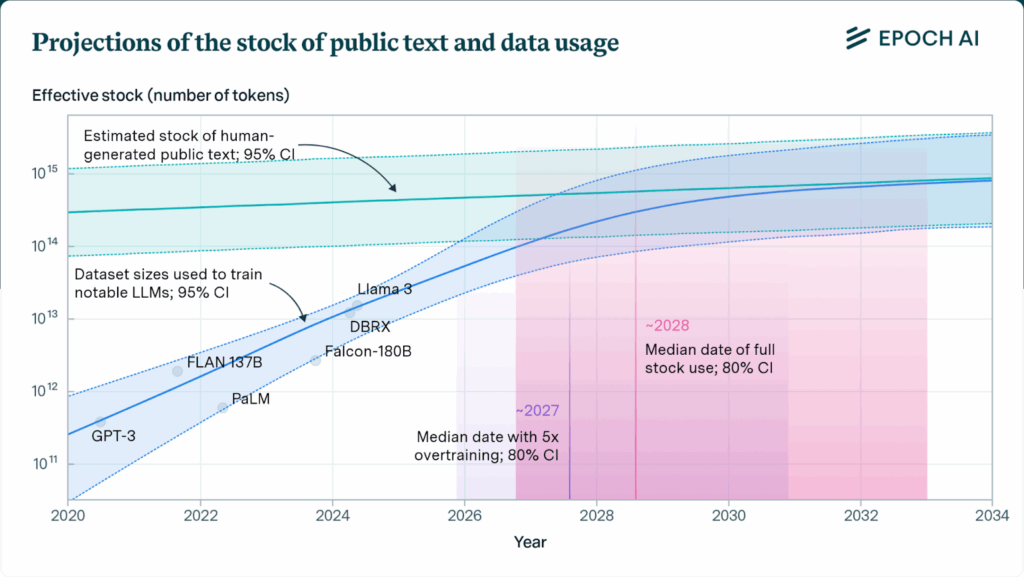
Graph (fig.1) illustrates the number of existing human-generated texts that are publicly available. And the different LLMs and the speed at which they’re digesting the information.
In essence, two main bottlenecks would be the overall availability of data, and the rate at which society produces genuinely-human created content (affected by the ease of producing AI materials rather than creating organic data given the lack of protections in place). With improvements in model scaling and computing efficiency the impact of these constraints can be slowed:
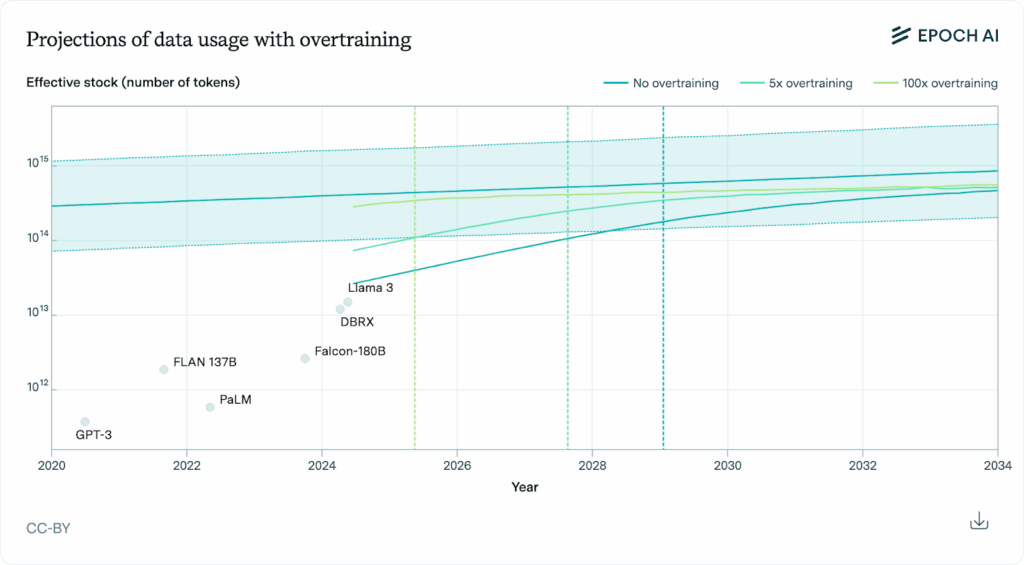
The graph (fig.2) shows the growth in training dataset sizes (measured in effective stock of tokens) against the available stock of data over time. It compares three scenarios—no overtraining (compute-optimal scaling), 5x overtraining, and 100x overtraining—showing that aggressive overtraining depletes the data stock much faster, potentially by 2025, while no overtraining delays exhaustion until around 2030.
But even with these adjustments, the data will still run out before 2030. This analysis mainly focuses on public human text data, but their estimates of the data available out there delineates all that exists:
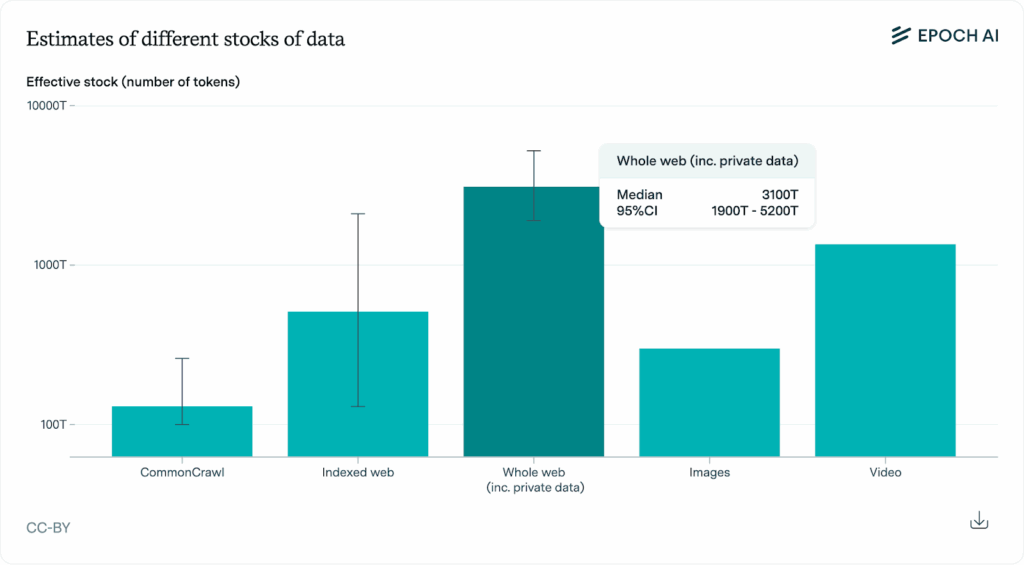
This bar chart (fig.3) estimates how much usable data (in tokens) exists in different sources: Common Crawl, the indexed web, the entire web including private data, images, and video. It shows that the whole web and video contain the largest estimated data stocks, with substantial uncertainty ranges indicated by the error bars.
As publicly and legally available data becomes increasingly scarce, one can see a clear incentive for malicious behaviour to arise. From training on copyrighted data, to scraping content online without users explicit consent, adopting artistic styles of artists without permission. In fact, companies are already edging (some leaping, hello OpenAI, apologies Miyazaki) and pushing the limits on this. On April 14, 2025, Reuters reported that Meta (parent company of Facebook and Instagram) will start using the public posts, comments, and interactions of its users to train its AI models across all its platforms within the EU, effective on May 27, 202518.
Companies are also exploring other ways to bypass this major problem, such as generating synthetic data. AI-generated data would be a potential solution to the impending scarcity of data and a workaround to IP and privacy issues. Indeed, a plausible strategy could be having the AI models use “a technique called test-time compute in which the AI responds to a prompt by breaking it down into multiple tasks. Instead of spitting out an answer instantaneously, the model spends extra time “thinking” before generating an outcome.
These higher-quality responses could be turned into a new training data set for the AI, which in theory, could improve its responses19.”
Unfortunately, it’s not that simple. A study that looked into using synthetic data for training models revealed that the “model collapse” phenomenon can arise. This leads to lower-quality outputs being produced, which eventually circulate on the web and are later used as training data for future models. In the end, it could create a problematic loop that ends in the inevitable collapse of the model20. All this to say that we are currently at a stage where there seems to be a lack of viable solutions to address the rapid and wide consumption of organic data necessary for AI models to continuously improve.
As the seas calm from OpenAI’s controversial image-generation rollout and the echoes of the Writer’s Guild of America strike still linger, it’s clear that Generative AI has copyright problems. Miyazaki’s misgivings, the collective action of writers, and the uptake in infringement claims underscore the need for a solution. Not just for the sake of creatives, but for the continued advancement of AI as well.
Given the issues we’ve outlined above and the ongoing controversies surrounding the relationship between AI and copyright, it’s easy to fall into a dichotomy: human creators vs AI companies. Strong copyrights don’t just protect creators, they are also the backbone of innovation, incentivizing original work, which in turn prevents AI models from plateauing.
As copyright adjusts to an AI world, new models have to emerge to align the interests of creators of AI companies and creators. Imagine a system where creators could opt in to share their work, earn automatic royalties and let AI learn without infringing. A new marketplace that ensures that we never run out of original ideas. Disney’s and OpenAI’s recent $1 billion investment and licensing partnership, enabling Sora to generate fan-prompted videos and images from 200+ Disney, Marvel, Pixar, and Star Wars characters, illustrates one such win-win collaboration21. Copyright law needs to catch up fast, or we risk letting the next generation of AI to train on a world starved of creativity.
1. Generative AI Is A Crisis For Copyright Law. Forbes. April 2025. Available at: https://www.forbes.com/sites/hessiejones/2025/04/03/generative-ai-is-a-crisis-for-copyright-law/
2. ChatGPT’s Studio Ghibli AI Art Trend Is an Insult to Life Itself. Gizmodo. March 2025. Available at: https://gizmodo.com/open-ai-ghibli-trend-miyazaki-chatgpt-2000581679
3. A transformer model understands text by looking at a sequence of words at once and learning how the words relate to each other, which allows it to capture context more accurately than word-by-word approaches.
4. An autoencoder is a type of neural network that learns important features in data without labels (unsupervised learning) by compressing inputs into an efficient representation and then reconstructing the original input as accurately as possible from this compressed code.
5. Interactions Between Artificial Intelligence and Intellectual Property Law. Max Planck Institute for Innovation and Competition. Available at: https://www.ip.mpg.de/en/projects/details/interactions-between-artificial-intelligence-and-intellectual-property-law.html
6. Copyright history. Intellectual Property Rights Office. Available at: Copyright HistoryIntellectual Property Rights Officehttps://intellectualpropertyrightsoffice.org › copyright_...
7. Copyright - Your rights. Europa.eu. Available at: https://europa.eu/youreurope/business/running-business/intellectual-property/copyright/index_en.htm
8. Gaffar H., Albarashdi S. Copyright Protection for AI-Generated Works: Exploring Originality and Ownership in a Digital Landscape. Asian Journal of International Law. Published online on: 23 January 202. Available at https://www.cambridge.org/core/journals/asian-journal-of-international-law/article/copyright-protection-for-aigenerated-works-exploring-originality-and-ownership-in-a-digital-landscape/12B8B8D836AC9DDFFF4082F7859603E3
9. Human Authorship Requirement Continues To Pose Difficulties for AI-Generated Works. Perkins Coei. February 2024. Available at: https://perkinscoie.com/insights/article/human-authorship-requirement-continues-pose-difficulties-ai-generated-works
10. AI Can Create a Painting but It Can’t Register a Copyright in the Painting. Perkins Coei. May 2022. Available at: https://perkinscoie.com/insights/blog/ai-can-create-painting-it-cant-register-copyright-painting
11. AI and authorship: Navigating copyright in the age of generative AI. DLA Piper. February 2025. Available at: https://www.dlapiper.com/en/insights/publications/2025/02/ai-and-authorship-navigating-copyright-in-the-age-of-generative-ai
12. Art and artificial intelligence collide in landmark legal dispute. Financial Times. January 2023. Available at: https://www.ft.com/content/d691d599-3cdb-48d8-9824-9b2784a17d90
13. Getty Images v Stability AI: Getty’s copyright case against Stability AI fails. Pinsent Maisons. November 2025. Available at: https://www.pinsentmasons.com/out-law/news/gettys-copyright-case-against-stability-ai-fails
14. NYT v. OpenAI: The Times’s About-Face. Harvard Law Review. April 2024. Available at: https://harvardlawreview.org/blog/2024/04/nyt-v-openai-the-timess-about-face/
15. Will we run out of data? Limits of LLM scaling based on human-generated data. Epoch AI. June 2024. Available at: https://epoch.ai/blog/will-we-run-out-of-data-limits-of-llm-scaling-based-on-human-generated-data
16. Will we run out of data? Limits of LLM scaling based on human-generated data. Epoch AI. June 2024. Available at: https://epoch.ai/blog/will-we-run-out-of-data-limits-of-llm-scaling-based-on-human-generated-data
17. Will we run out of data? Limits of LLM scaling based on human-generated data. Epoch AI. June 2024. Available at: https://epoch.ai/blog/will-we-run-out-of-data-limits-of-llm-scaling-based-on-human-generated-data
18. Meta to use public posts, AI interactions to train models in EU. Reuters. April 2025. Available at: https://www.reuters.com/technology/artificial-intelligence/meta-use-public-posts-ai-interactions-train-models-eu-2025-04-14/
19. Data Is Fueling the AI Revolution. What Happens When It Runs Out?. Cal Alumni Association. March 2025. Available at: https://alumni.berkeley.edu/california-magazine/online/data-is-fueling-the-ai-revolution-what-happens-when-it-runs-out/
20. Shumailov, I., Shumaylov, Z., Zhao, Y. et al. AI models collapse when trained on recursively generated data. Nature. Published online: July 2024. Available at: https://www.nature.com/articles/s41586-024-07566-y
21. The Walt Disney Company and OpenAI reach landmark agreement to bring beloved characters from across Disney’s brands to Sora. OpenAI. December 2025 Available at: https://openai.com/index/disney-sora-agreement/